¿Qué son los cubos OLAP?
 Image via Wikipedia
Image via WikipediaUn cubo OLAP, OnLine Analytical Processing o Procesamiento Analítico en Línea, término acuñado por Edgar Frank Coddde EF Codd & Associates, encargado por Arbor Software (en la actualidad Hyperion Solutions), es una base de datos multidimensional, en la cual el almacenamiento físico de los datos se realiza en un vector multidimensional. Los cubos OLAP se pueden considerar como una ampliación de las dos dimensiones de una hoja de cálculo.
A menudo se pensaba que todo lo que los usuarios pueden querer de un sistema de información se podría hacer de una base de datos relacional. No obstante Codd fue uno de los precursores de las bases de datos relacionales, por lo que sus opiniones fueron y son respetadas.
 Image via Wikipedia Image via Wikipedia |
| Diseño en copo de nieve de un Cubo OLAP |
Las bases de datos relacionales son más adecuados para registrar datos provenientes de transacciones (conocido como OLTP o procesamiento de transacciones en línea). Aunque existen muchas herramientas de generación de informes para bases de datos relacionales, éstas son lentas cuando debe explorarse toda la base de datos. Por ejemplo, una empresa podría analizar algunos datos financieros por producto, por período, por ciudad, por tipo de ingresos y de gastos, y mediante la comparación de los datos reales con un presupuesto. Estos parámetros en función de los cuales se analizan los datos se conocen como dimensiones.

Para acceder a los datos sólo es necesario indexarlos a partir de los valores de las dimensiones o ejes. El almacenar físicamente los datos de esta forma tiene sus pros y sus contras. Por ejemplo, en estas bases de datos las consultas de selección son muy rápidas (de hecho, casi instantáneas). Pero uno de los problemas más grandes de esta forma de almacenamiento es que una vez poblada la base de datos ésta no puede recibir cambios en su estructura. Para ello sería necesario rediseñar el cubo.
En un sistema OLAP puede haber más de tres dimensiones, por lo que a los cubos OLAP también reciben el nombre de hipercubos. Las herramientas comerciales OLAP tienen diferentes métodos de creación y vinculación de estos cubos o hipercubos (véase Tipos de OLAP en el artículo sobre OLAP).

La principal característica que potencia a OLAP, es que es lo más rápido a la hora de ejecutar sentencias SQL de tipo SELECT, en contraposición con OLTP que es la mejor opción para operaciones de tipo INSERT, UPDATE Y DELETE.
Construir sistemas OLAP con cubos
Cada vez que un usuario quiere ver un valor agregado el sistema debe calcularlo a partir de los datos del datamart, en lo que se invierte un tiempo apreciable. Los sistemas OLAP, OnLine Analytical Processing, pretenden minimizar estos tiempos mientras el usuario interactúa on-line con los valores.
Como en el cálculo de un valor agregado intervienen varias dimensiones o jerarquías inferiores, lo habitual es que el sistema OLAP calcule y almacene algunos de estos valores (sino todos) gracias a procesos en segundo plano (background). Así se consigue que los tiempos de cálculo no afecten a los usuarios. Los agregados se almacenan en una base de datos (relacional o multidimensional según la arquitectura empleada). De esta manera cuando un responsable quiere ver una medida para un cierto conjunto de
miembros dimensionales, el valor se leerá en una base de datos en lugar de calcularse sobre la marcha. Esto mejora considerablemente la respuesta del sistema, que a su vez fomenta la interacción online y aumenta la probabilidad de que el usuario encuentre la información que le ayude a tomar su decisión. Además, los nombres de las medidas, dimensiones y jerarquías se entienden fácilmente, no son crípticos ni abreviados.
La parte fundamental de un sistema OLAP es el cubo y los agregados preprocesados que contiene. Existen tres arquitecturas básicas, cada una con sus ventajas y desventajas.

¿Qué son las pivot tables?
También llamadas tablas dinámicas, son una herramienta de sumarización de datos. Deben su nombre a la rotación (pivoting en ingles) de los datos dentro de la misma. Esto se logra simplemente arrastrando los campos requeridos a la zona deseada.
Sumarización
Las pivot se encargan de “sumarizar” los datos, esto quiere decir que agrupara la información textual similar, y la información numérica referida a esos datos será sumada, como se logra ver en el ejemplo. Aquí notamos las ventas totales para cada uno de los clientes.

Ahora un ejemplo con un poco más de complejidad, en este caso podemos ver como para cada uno de los países se muestran los clientes en él y, además cuanto se ha vendido por cada uno de los trimestres (Quarter) del año.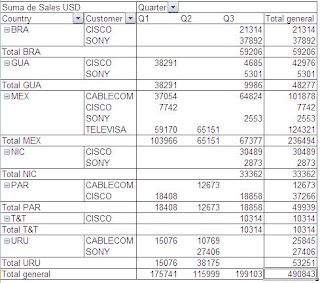

Rotación
Dentro de las tablas dinámicas podemos mover cada uno de los campos según nuestra conveniencia, a este efecto se le denomina “Rotación.” En el ejemplo se ha movido el campo “Product Group” para poder visualizar la información de cada cliente a un mayor detalle.

Formato adecuado para una base de datos de la cual se construirá una tabla dinámica
No se puede construir una pivot en base a cualquier tipo de base de datos, la base de datos debe ser completamente consistentey todas las columnas deben tener encabezado. La base de la izquierda es un claro ejemplo de cómo NO debe ser una base de datos para tablas dinámicas.

Construcción de una tabla dinámica

Para crear una tabla dinámica opivot table en Office 2007 basta con ir a la pestaña Insertar, seleccionar tabla dinámica, y posteriormente hacer clic en la opción tabla dinámica.

En la ventana emergente seleccionamos el rango y el lugar donde deseamos insertar la tabla dinámica (Nueva hoja de cálculo, Hoja de cálculo existente) Para finalizar, hacemos clic en aceptar y la tabla dinámica se presentara de la siguiente manera:

También podemos visualizar la presentación clásica de la pivot haciendo clic con el botón derecho sobre la tabla, luego opciones, pestaña Mostrar y habilitamos la opción “Diseño de tabla dinámica clásica”

Al hacer clic en aceptar ahora el diseño de la tabla dinámica se mostrará como sigue, abajo coloco la descripción de cada una de las zonas de la tabla dinámica.

Del lado derecho de la pantalla tendremos la lista de campos a elegir y las posiciones donde deberemos colocarlos de acuerdo al análisis que nos gustaría realizar.
De esta lista de campos podemos arrastrar los requeridos a las diferentes zonas de la tabla dinámica, o bien, a las áreas que están debajo de esa misma lista, no hay diferencia hacia donde las arrastremos, el resultado será el mismo.

Modificación / Actualización
Cuando intentemos modificar una tabla dinámica no podremos hacerlo desde sí misma, debido a que está ligada a una base de datos, es por eso que deberemos ir hasta ella para lograr aplicar los cambios correctamente. En el ejemplo, para la línea 21 modificaremos el Quarter de Q3 a Q2.


Con los cambios realizados a la Base de datos deberemos actualizar la tabla dinámica, para que se vean reflejados, haciendo clic derecho sobre la misma y posteriormente en la opción “Actualizar
ENLACES RELACIONADOS
No hay comentarios:
Publicar un comentario